加密货币 三大交易所
加密货币 三大交易所随着ChatGPT等AIGC应用掀起大模型浪潮,算力层作为基础设施,成为最先受益的产业。
然而,算力需求大、费用昂贵等问题,已成为企业落地大模型的普通痛点,更可能制约AI向前发展:大模型参数日益增长,而算力供给瓶颈迫在眉睫,二者形成巨大矛盾。
如何探索更好的大模型算力方案,是业界共同关注的焦点。
近日,全球权威测评MLPerf 公布最新推理测评结果,这是MLPerf首度引入GPT大模型推理测试,参与热度再创纪录,收到了来自英伟达、英特尔、谷歌、高通等企业提交的13500多项性能结果。
在MLPerf Inference 3.1中,墨芯人工智能(Moffet AI)S30计算卡在大模型GPT-J(60亿参数)上,单卡、4卡、8卡的算力均获得第一。

这是墨芯在MLPerf上连续第三次卫冕。
此前墨芯曾在MLPerf Inference 2.0与2.1上,连续两届获得第一。

墨芯S30计算卡
墨芯的成绩,为大模型算力方案带来了可行的创新方向。
事实证明:结合AI模型与计算平台的软硬协同创新,能够释放更大的算力潜力。这也再度印证:以稀疏计算为代表的创新技术,将是大模型时代算力发展的关键。
墨芯参加的是MLPerf开放分区,据主办方MLCommons介绍,该分区旨在鼓励创新。因此参赛者可以通过软硬协同等方式,探索对算力的提升。
在MLPerf中的GPT-J大模型上,与4nm制程的H100纯硬件加速方案相比,12nm制程的墨芯S30计算卡通过「原创的双稀疏算法+硬件协同」方式,取得了高达1.8倍的优势。
本次测评的GPT-J模型是生成式AI模型,墨芯S30计算卡在8卡、4卡、单卡模式下,性能分别为170.59,91.57,23.28 (Sample/s),达到英伟达H100性能的1.6倍、1.8倍、1.8倍,展现出墨芯产品在AIGC类任务上的能力。

三度夺冠,大模型算力率先「交卷」,软硬协同持续创新——墨芯的产品实力数次经过MLPerf的严格检验,也探索出大模型算力发展的新路径。
稀疏计算——大模型「潜力股」获得市场认可墨芯接连的优异成绩,主要得益于基于稀疏化算法的软硬协同设计。
在大模型时代,稀疏计算的重要性不言而喻:AI模型大小与其稀疏化潜力成正比。
也就是说,当模型越大,算法上有更大稀疏的可能性,稀疏计算可加速的幅度也越高。对于一般大型语言模型,稀疏计算可带来数十倍加速。
墨芯独创的双稀疏算法,结合软硬协同设计,使墨芯Antoum?芯片成为全球首款高稀疏倍率AI芯片,支持高达32倍稀疏——这也正是墨芯在本次MLPerf中创新纪录的关键。
模型越大,稀疏计算的优势越明显——尤其是在GPT等大模型参数动辄上百亿、千亿的现状下,这使得墨芯的护城河更为稳固。
墨芯的产品实力与稀疏计算的大势所趋,也获得了业界的认可:墨芯商业化进程接连取得重要突破,助力企业加速AI应用。
就在近日,墨芯正式成为支持Byte MLPerf的供应商之一。
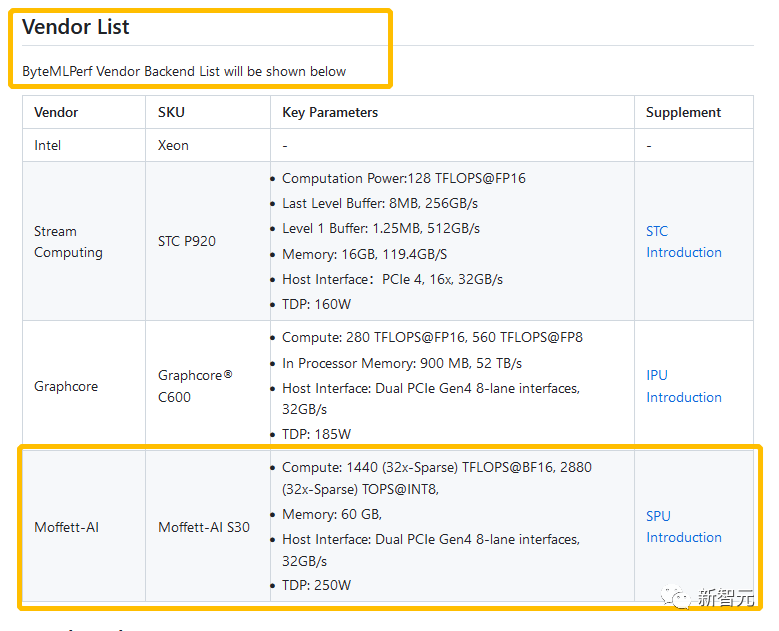
来源:Byte MLPerf网站
项目地址:https://github.com/bytedance/ByteMLPerf/blob/main/README.md
当前,墨芯AI计算平台已能够支持不同参数级别的大模型,包括 BLOOM, OPT, GPT-J,LLaMA,StableDiffusion等。
同时具有高吞吐、低延时、低功耗等特点,缓解算力之困,真正为企业带来「好用」、「用得起」的大模型算力方案。
带来根本性的算力变革,稀疏计算助力大模型发展墨芯的稀疏计算方案不仅能够缓解当前的算力难题,也为AI的持续发展打开新的空间。
稀疏计算减少了AI模型的计算量,这意味着能让大模型既在参数量上跃升若干个数量级的同时,又不产生过大的计算量,大模型参数增长与算力瓶颈的矛盾有望从根本上得到解决。
同时,由于计算量的减少,大模型的高算力需求、高功耗、高费用等痛点,也一并得到解决,实现「多赢」效果。

墨芯Antoum芯片:全球首款高稀疏倍率AI芯片,支持高达32倍稀疏
连续三届MLPerf的优异成绩,不仅是对墨芯产品实力的证明,也为业界带来新启示:在稀疏计算等技术的助力下,大模型的发展与应用有望迎来更广阔的施展空间,加速AIGC等应用在各行各业遍地开花。
关于MLPerf
MLPerf由图灵奖得主大卫?帕特森(David Patterson)联合谷歌、斯坦福、哈佛大学顶尖学术机构发起成立,是权威性最高、影响力最广的国际AI性能基准测试,以对迅速增长的AI计算需求与性能进行及时的跟踪测评。